Short introduction
Since 2025 Rapporteket has been provided as standalone container applications hosted in a kubernetes cluster. This document proposes methods that aim to provide an agile and robust process from development to deployment throughout the application lifecycle. As such, this document is also meant to be a primer for discussions on further improvements and refinements.
Container content
In this set-up, each registry will be represented as a standalone container application at Rapporteket, i.e. deployment will be based on registry specific container images. However, registries at Rapporteket all share a common set of features such as system environment and underlying software. These will all be established as a base container image that all registry container images are built upon. Both types of container images are described below.
Base container image
This image is built on Ubuntu LTS, common system libraries, R-release and common R-packages. Relevant system locale settings are also defined in this image. The outset is provided by rocker/r-verse that keeps track of whatever applies to Ubuntu LTS and R-release. Specifications for building the base image is provided by the corresponding Dockerfile.
Application container image
Registry R-shiny applications are added on top of the base image. Source code management for each registry application is hosted by the Rapporteket organization at GitHub where the respective Dockerfiles for building these images also resides.
Pipeline for continuous integration and delivery (CI/CD)
To ensure that changes to applications at Rapporteket can be delivered in a timely and reliable manner specific workflows are adopted. Pipelines for both the base image and registry applications are illustrated below.
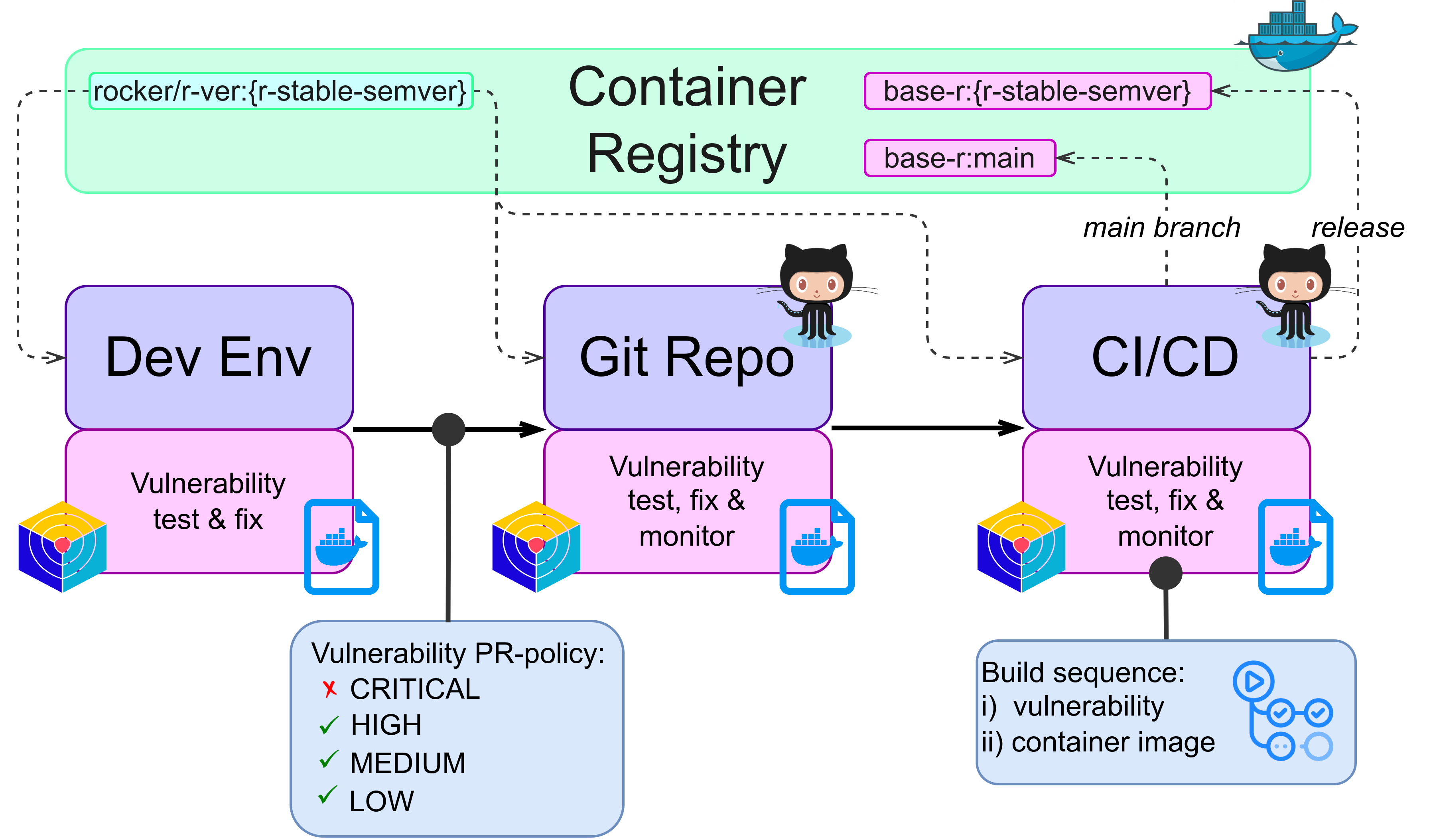
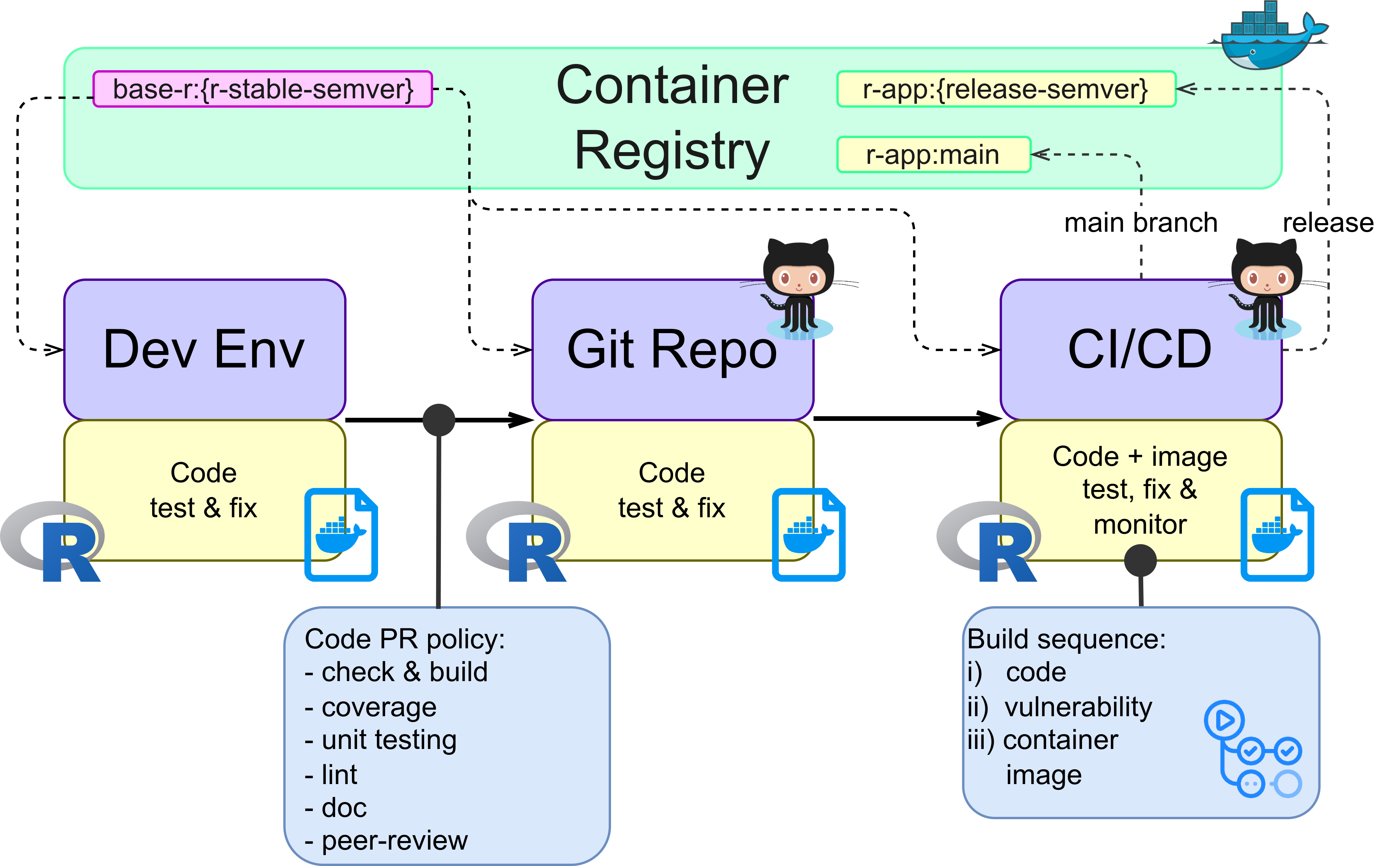
CI/CD tools and methods
Vulnerability test and monitoring of container images are performed by snyk. The base container image is monitored by weekly scans to detect emerging threats and changes to underlying code is also scanned as part of all pull requests to prevent new vulnerabilities from entering the main project. Currently, vulnerabilities with low or medium severity are accepted, high and critical are not.
As all code repositories are managed at GitHub, Github Actions are used to enforce policies and run CI/CD tasks. Execution of such tasks are both scheduled and triggered by code update requests.
Deployment THIS DOCUMENTATION IS NOT UP TO DATE!
In summary, deployment of registry applications follow a two step
process where development and deploy tasks are interconnected. In the
first step an application image is built from the main branch
and deployed to a quality assurance (QA) environment for
functional testing. After successful testing the second step can
commence where corresponding application code is tagged for release and
from which a new image is built and deployed to a production
environment. The overall process is illustrated below and further
details are described in the following sections. 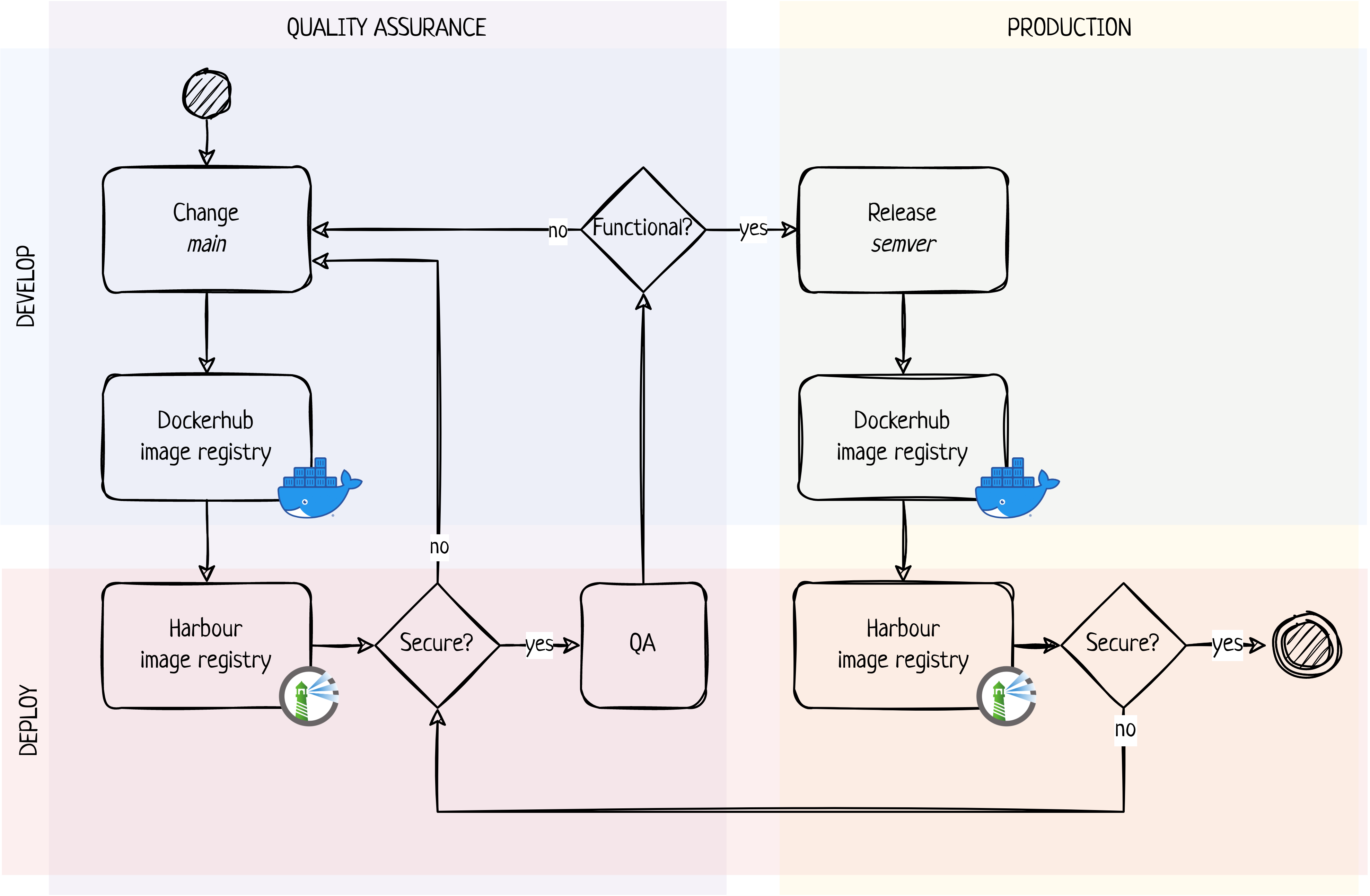
Quality assurance (QA)
Any changes applied to the main branch of the application code repository will trigger a build pipeline that if successful will push a new application image to the Dockerhub image registry. Any new image tagged by the name of the main branch in the Dockerhub image registry will trigger the deploy pipeline where the new image is pulled by the Harbour image registry and scanned for vulnerabilities. If this scanning is not successful, i.e. that unacceptable security issues are identified, a summary of relevant issues is reported to the development team via Rapporteket standard email inbox. Upon a successful vulnerability scanning the image will be deployed to the QA environment from where it can be tested, e.g. by an end user test team. If tests are successful the release process can commence, and if not the QA-loop will have to start all over again. The QA deploy step is fully automatic and will trigger on any changes to the main code branch.
Production
Once tests are accepted a new release version of the corresponding code will be made and tagged by use of semantic versioning. A new release will trigger an automated publish pipeline that will push a new image to the Dockerhub image registry. This image is tagged according to the version number of the code release and a static “production” tag that will serve the same purpose at the often used latest tag. These images will be pulled by the Harbour image registry and scanned for vulnerabilities following the exact same approach as for the QA process. When successful, the application image will be deployed to the production environment. In case a roll-back is needed, any existing image tagged with a semantic version number may be re-tagged with the static “production” tag. For this proof of concept, a roll-back will be part of the CI-process in either the development or deployment workflow. Overall, the production deploy step may therefore apply both automated and manual processes. This approach may well be adjusted to meet not yet known future demands for tighter control and change management.
Vulnerability scanning
In the above, the deployment process is described in the case when application code changes and a new version is to be deployed. Since new vulnerabilities may well emerge for an application image that has already been deployed to the QA or production environment security scanning will also be run on a schedule. In this case and if new and unacceptable threats are identified the application image will be left running but the results of the vulnerability scanning will be reported in the same way as describe above.